Davis AI ayuda a garantizar que todos los datos de la plataforma Dynatrace sean confiables y precisos para el análisis empresarial, la orquestación inteligente de la nube y la automatización confiable
Data Observability para su plataforma de análisis
Dynatrace (NYSE: DT), líder en observabilidad y seguridad unificada, anuncia nuevas capacidades de observabilidad de datos impulsadas por IA para su plataforma de análisis y automatización.
Con Dynatrace® Data Observability, los equipos pueden confiar en todos los datos de observabilidad, seguridad y eventos comerciales en Dynatrace para impulsar el motor de IA Davis® de la plataforma para ayudar a eliminar falsos positivos y ofrecer análisis comerciales confiables y automatizaciones confiables.
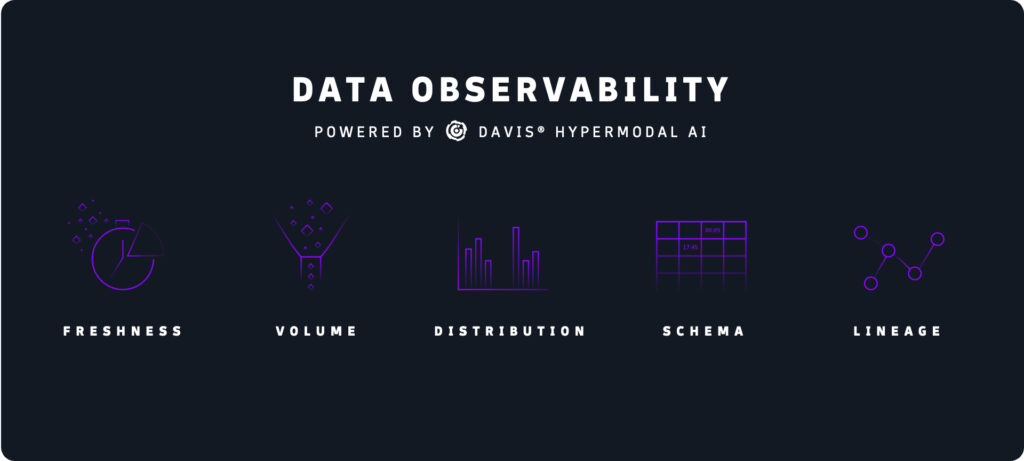
Data Observability de Dynatrace permite que los equipos de análisis empresarial, ciencia de datos, DevOps, SRE, seguridad y otros ayuden a garantizar la alta calidad de todos los datos en la plataforma Dynatrace®. Esto complementa las capacidades de enriquecimiento y limpieza de datos existentes de la plataforma proporcionadas por Dynatrace OneAgent® para ayudar a garantizar la alta calidad de los datos recopilados a través de otras fuentes externas, incluidos estándares de código abierto, como OpenTelemetry, e instrumentación personalizada, como registros y APIs de Dynatrace. Permite a los equipos realizar un seguimiento de la actualidad, el volumen, la distribución, el esquema, el linaje y la disponibilidad de estos datos de origen externo, lo que reduce o elimina la necesidad de herramientas de limpieza de datos adicionales.
“Dynatrace, con su tecnología OneAgent, nos brinda un alto nivel de confianza en que los datos que impulsan nuestro análisis y automatización están son saludables. La plataforma también es muy flexible, lo que nos permite aprovechar fuentes de datos personalizadas y abrir estándares, como OpenTelemetry”, dijo Kulvir Gahunia, Director de la Oficina de Confiabilidad del Sitio de TELUS. “Las nuevas capacidades de observabilidad de datos de Dynatrace ayudarán a garantizar que los datos de estas fuentes personalizadas también sean de alta calidad para nuestros análisis y automatización. Esto nos ahorrará tener que limpiar los datos manualmente y reducirá la necesidad de herramientas de limpieza de datos”.
Los datos de alta calidad son fundamentales para las organizaciones que dependen de ellos para fundamentar estrategias comerciales y de productos, optimizar y automatizar procesos e impulsar mejoras continuas. Sin embargo, la escala y la complejidad de los datos de los ecosistemas de nube modernos, combinadas con el aumento de uso de soluciones de código abierto, APIs abiertas y otras instrumentaciones personalizadas, dificultan alcanzar este objetivo.
Al adoptar técnicas de observabilidad de datos, las organizaciones pueden mejorar la disponibilidad, confiabilidad y calidad de los datos durante todo el ciclo de vida de éstos, desde la ingesta hasta el análisis y la automatización. Según Gartner®, «para 2026, el 30% de las empresas que implementan arquitecturas de datos distribuidas habrán adoptado técnicas de observabilidad de datos para mejorar la visibilidad sobre el estado de su panorama de datos, frente a menos del 5% en 2023». 1
Dynatrace Data Observability trabaja con otras tecnologías centrales de la plataforma Dynatrace® , incluida la IA hipermodal de Davis que combina capacidades de IA predictivas, causales y generativas, para brindar a los equipos basados en datos los siguientes beneficios:
Actualización: ayuda a garantizar que los datos utilizados para el análisis y la automatización estén actualizados y sean oportunos y alerta sobre cualquier problema, por ejemplo, inventario agotado, cambios en la fijación de precios de productos y anomalías de las marcas de tiempo.
Volumen: monitorea aumentos, disminuciones o brechas inesperadas en los datos (por ejemplo, la cantidad de clientes reportados que utilizan un servicio específico), lo que puede indicar problemas no detectados.
Distribución: monitorea patrones, desviaciones o valores atípicos de la forma esperada en que se distribuyen los valores de datos en un conjunto de datos, lo que puede señalar problemas en la recopilación o el procesamiento.
Esquema: realiza un seguimiento de la estructura de datos y alerta sobre cambios inesperados, como campos nuevos o eliminados, para evitar resultados inesperados como informes y paneles rotos.
Linaje: ofrece detalles precisos sobre la causa raíz de los orígenes de los datos y los servicios que afectarán posteriormente, lo que ayuda a los equipos a identificar y resolver proactivamente los problemas de datos antes de que afecten a los usuarios o clientes.
Disponibilidad: aprovecha las capacidades de observabilidad de la infraestructura de la plataforma Dynatrace para observar el uso de servidores, redes y almacenamiento de los servicios digitales, alertando sobre anomalías como el tiempo de inactividad y la latencia, para proporcionar un flujo constante de datos de estas fuentes para un análisis y una automatización saludables.

«La calidad y confiabilidad de los datos son vitales para que las organizaciones funcionen, innoven y cumplan con las regulaciones de la industria», dijo Bernd Greifeneder, CTO de Dynatrace. “Una solución de análisis valiosa debe detectar problemas en los datos que alimentan el análisis y la automatización lo antes posible. Dynatrace OneAgent siempre ha ayudado a garantizar que los datos que recopila sean de la más alta calidad. Al agregar capacidades de observabilidad de datos a nuestra plataforma unificada y abierta, estamos permitiendo a nuestros clientes aprovechar el poder de los datos de más fuentes para obtener más posibilidades de análisis y automatización, al tiempo que mantienen la salud de sus datos, sin necesidad de herramientas adicionales”.
Se espera que Dynatrace Data Observability esté disponible de forma general para todos los clientes de Dynatrace SaaS dentro de los 90 días posteriores a este anuncio. Visite el blog de Observabilidad de datos de Dynatrace para obtener más información.
Related News

El 65 % de Ingeniería Agroindustrial son mujeres
El Departamento de Ingeniería Agroindustrial (DIA) de la Universidad Autónoma Chapingo (UACh) presentó su PrimerMás información…